|
 |
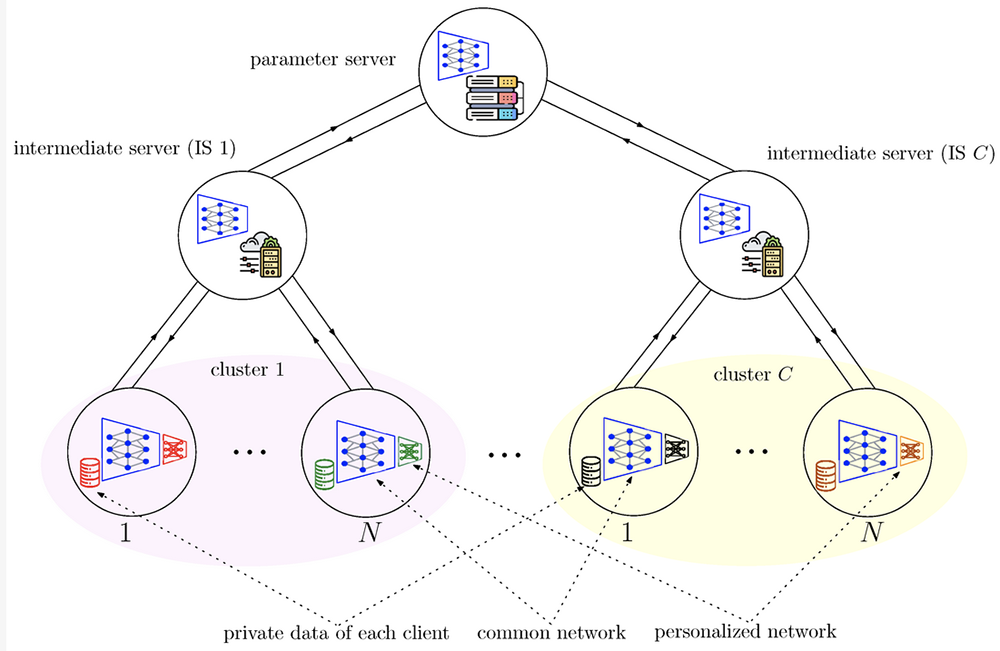
A hierarchical personalized federated learning (HPFL) framework wtih a common network (blue) and small personalized headers (red, green, black, orange. (Fig. 2 from the paper) |
|
Multi-tasking (MTL) is a powerful technique for simultaneously learning multiple related tasks that can improve overall network system performance, training speed, and data efficiency. MTL leverages synergy among multiple related tasks. In an MTL setting, each task has a single common encoder network to map the raw data into a lower dimensional shared representation space, in addition to a unique client-specific header network to infer task related prediction values from shared representation. MTL is particularly suitable for distributed learning settings where no single entity has all the data and labels for all of the multiple different tasks.
Personalized federated learning (PFL) can be achieved through MTL in the context of federated learning (FL) where tasks are distributed across clients, referred to as personalized federated MTL (PF-MTL). Unfortunately, the system performance is degraded by statistical heterogeneity caused by differences in the task complexities across clients and the non-identically independently distributed (non-i.i.d.) characteristics of local datasets.
To overcome this degradation, Clark School faculty and students have developed FedGradNorm, a distributed dynamic weighting algorithm that balances learning speeds across tasks by normalizing the corresponding gradient norms in PF-MTL. Their paper, Personalized Federated Multi-Task Learning over Wireless Fading Channels has been published in the MDPI open-access journal Algorithms. The paper was written by ECE Ph.D. students Matin Mortaheb and Cemil Vahapoglu and their advisor, Professor Sennur Ulukus (ECE/ISR). Ulukus was recently named the chair of the Electrical and Computer Engineering Department.
The paper proves an exponential convergence rate for FedGradNorm and proposes a hierarchical over-the-air (HOTA) version of FedGradNorm—HOTA-FedGradNorm—by utilizing over-the-air aggregation (OTA) with FedGradNorm in a hierarchical FL (HFL) setting. HOTA-FedGradNorm takes into consideration characteristics of wireless communication channels. It is designed to have efficient communication between the parameter server (PS) and clients in the power- and bandwidth-limited regime.
FedGradNorm and HOTA-FedGradNorm were tested using MT facial landmark (MTFL) and wireless communication system (RadComDynamic) datasets. The results indicate that both frameworks are capable of achieving a faster training performance compared to equal-weighting strategies. FedGradNorm could ensure faster training and more consistent performance and could compensate for the effects of imbalanced allocation of data among the clients. Tasks with insufficient data are also eligible for fair training since the weights of task losses are adjusted with respect to training speeds to encourage the slow learning tasks. HOTA-FedGradNorm provides robustness under negative channel effects while having faster training compared to naive equal weighting strategy.
Related Articles:
Narayan receives NSF funding for shared information work
Work on RIS-aided mmWave beamforming named a ‘best paper’
Michael Fu part of $1M NSF grant to model, disrupt illicit kidney trafficking networks
Connected autonomous vehicles hold promise for alleviating traffic 'shock waves'
Alumni Profile: Yijie Han
Michael Fu part of NSF project to improve kidney transplant access and decision-making
Alumnus Ravi Tandon earns tenure at University of Arizona
S. Raghu Raghavan is PI for NSF project on illicit drug trafficking networks
Alumnus Rajiv Laroia honored with IEEE Alexander Graham Bell Medal
Path planning for bridge inspection robots
November 10, 2022
|
