 |
|
|
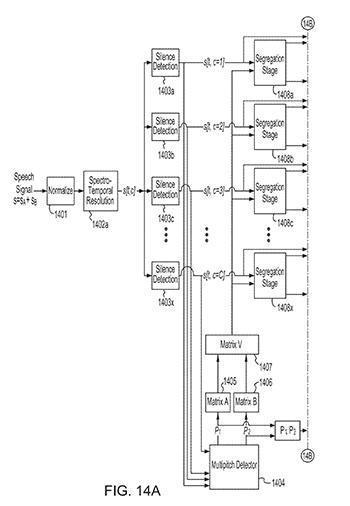
Fig 14A from the patent: A block diagrams of a speech extraction system. |
|
Professor Carol Espy-Wilson (ECE/ISR) and her former student Srikanth Vishnubhotla (EE Ph.D. 2010) have been issued US Patent 9,886,967 for “Systems and Methods For Speech Extraction.” The patent was issued Feb. 6, 2018.
Vishnubhotla currently is an engineer at Apple in Cupertino, Calif.
About the patent
Technologies such as automatic speech recognition and speaker identification) often encounter speech signals that are obscured by external sources of noise and interference such as background noise and other speakers. Similarly, hearing-aid and cochlear implant device users are often plagued by external disturbances that interfere with the speech signals they are struggling to understand. These disturbances can become so overwhelming that users often prefer to turn their medical devices off. As a result, these medical devices are useless to some users in certain situations.
A speech extraction process can improve the quality of the speech signals produced by these technologies and devices.
Existing speech extraction processes often attempt to perform the function of speech separation (e.g., separating interfering speech signals or separating background noise from speech) by relying on multiple sensors (e.g., microphones) to exploit their geometrical spacing to improve the quality of speech signals. However, most existing communication systems and medical devices only include one (or some other limited number) sensor. Existing speech extraction processes, therefore, are not suitable for use with these systems or devices without expensive modification.
Thus, a need exists for an improved speech extraction process that can separate a desired speech signal from interfering speech signals or background noise using a single sensor and can also provide speech quality recovery that is better than the multi-microphone solutions.
This invention relates to speech extraction, and more particularly, to system and methods of speech extraction. In the invention, a processor-readable medium stores code representing instructions to cause a processor to receive an input signal having a first component and a second component. An estimate of the first component of the input signal is calculated based on an estimate of a pitch of the first component of the input signal. An estimate of the input signal is calculated based on the estimate of the first component of the input signal and an estimate of the second component of the input signal. The estimate of the first component of the input signal is modified based on a scaling function to produce a reconstructed first component of the input signal. The scaling function is a function of at least one of the input signal, the estimate of the first component of the input signal, the estimate of the second component of the input signal, or a residual signal derived from the input signal and the estimate of the input signal.
Related Articles:
Espy-Wilson and Pruthi win in University's Business Plan Competition
Wu and Wong granted U.S. patent for method to detect counterfeiting
NSF funds Shamma, Espy-Wilson for neuromorphic and data-driven speech segregation research
‘Priming’ helps the brain understand language even with poor-quality speech signals
New UMD Division of Research video highlights work of Simon, Anderson
Neural and computational mechanisms underlying musical enculturation
NSF funding to Fermüller, Muresanu, Shamma for musical instrument distance learning using AI
New system could improve thermal devices used to check our temperatures and respiration
Espy-Wilson is PI for NSF project to improve 'speech inversion' tool
New research uses reverberations for better automatic speech recognition
March 28, 2018
|
