 |
|
|
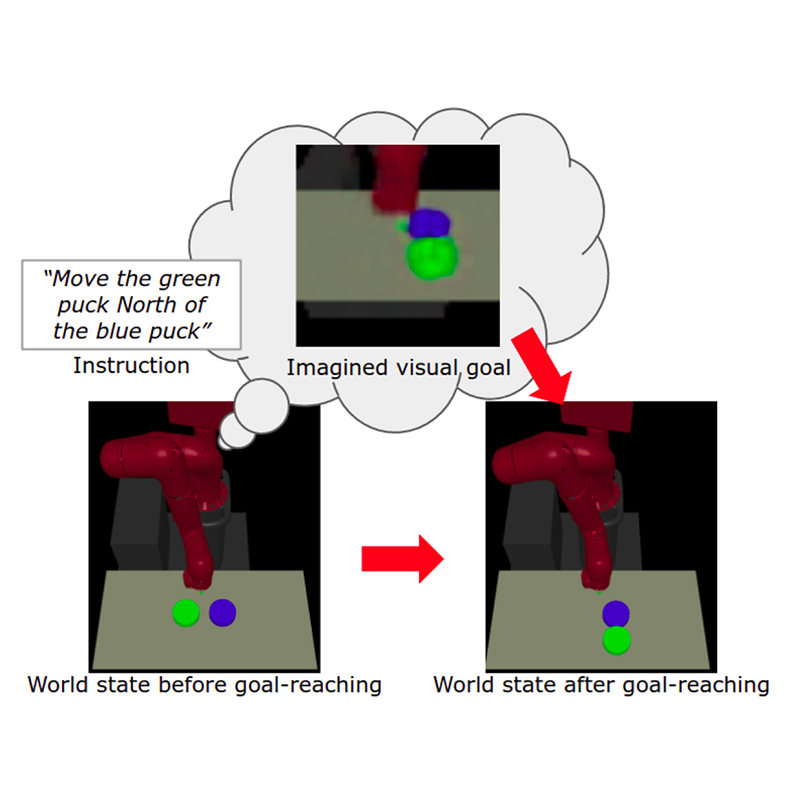
The agent learns to execute instructions by synthesizing and reaching visual goals from a learned latent variable model. (Figure 1 from the paper) |
|
Building robotic agents that can follow instructions in physical environments is one of the most enduring challenges in robotics and artificial intelligence, dating back to the 1970s. Traditionally, methods for accomplishing this assume the agent has prior linguistic, perceptual, and procedural knowledge. However, recently deep reinforcement learning (RL) has emerged as a promising framework for instruction-following tasks. In this method, policies could be learned end-to-end, typically by training neural networks to map joint representations of observations and instructions directly to actions.
To design agents that exhibit intelligence and learn through interaction, roboticists will need to incorporate cognitive capabilities like imagination, one of the hallmarks of human-level intelligence.
Following Instructions by Imagining and Reaching Visual Goals, a new paper by John Kanu, Eadom Dessalene, Xiaomin Lin, ISR-affiliated Associate Research Scientist Cornelia Fermüller (UMIACS), and ISR-affiliated Professor Yiannis Aloimonos (CS/UMIACS) addresses the need to incorporate explicit spatial reasoning to accomplish temporally extended tasks with minimal manual engineering.
The researchers present a novel framework for learning to perform temporally extended tasks using spatial reasoning in the RL framework, by sequentially imagining visual goals and choosing appropriate actions to fulfill imagined goals. The framework, called Instruction-Following with Imagined Goals (IFIG), integrates a mechanism for sequentially synthesizing visual goal states and methods for self-supervised state representation learning and visual goal reaching. IFIG requires minimal manual engineering, operates on raw pixel images, and assumes no prior linguistic or perceptual knowledge. It learns via intrinsic motivation and a single extrinsic reward signal measuring task completion.
The authors validate their method in two environments with a robot arm in a simulated interactive 3D environment, and find IFIG is able to decompose object-arrangement tasks into a series of visual states describing sub-goal arrangements. Their method outperforms two flat architectures with raw-pixel and ground-truth states, and a hierarchical architecture with ground-truth states on object arrangement tasks.
Without any labelling of ground-truth state, IFIG outperforms methods that have access to ground-truth state, as well as methods without goal-setting or explicit spatial reasoning. Through visualization of goal reconstructions, the authors show their model has learned instruction-conditional state transformations, suggesting an ability to perform task-directed spatial reasoning.
Related Articles:
A learning algorithm for training robots' deep neural networks to grasp novel objects
New Research Helps Robots Grasp Situational Context
CSRankings places Maryland robotics at #10 in the U.S.
Seven UMD Grand Challenges projects include ISR and MRC faculty
ArtIAMAS receives third-year funding of up to $15.1M
Autonomous drones based on bees use AI to work together
'OysterNet' + underwater robots will aid in accurate oyster count
Game-theoretic planning for autonomous vehicles
New GAMEOPT framework will help future autonomous vehicles safely navigate unsignalized intersections
Manocha Receives 2022 Verisk AI Faculty Research Award
February 14, 2020
|
